Процессы, потоки и конкурентное выполнение программ
Прочитав эту статью вы сможете различать многопроцессность, многопоточность, параллелизм, конкурентное выполнение программ и будете обладать базовыми определениями этих понятий. По мере повествования я буду указывать ссылки на дополнительные материалы, а конце заметки я укажу ссылки на дополнительные материалы, ознакомившись с которыми, вы сможете получить более исчерпывающую информацию.
Все нижесказанное в первую очередь относится к POSIX-совестимым системам. В Windows всё чуть иначе и я не буду останавливаться на различиях. Если вы заметили неточность или хотели бы, чтобы я добавил что-то интересное, напишите мне.
Структура процесса
В Unix-подобных системах процесс по существу является экземпляром программы. Одна и та же программа может породить множество процессов. Если проводить аналогию с ООП, то программа это класс, а процесс — объект. Однако на этом сходство заканчивается.
Обычно программа представлена в виде файла, который содержит информацию о том, как создавать процессы. В такую информацию входит:
- Идентификация двоичного формата (
a.out,coff,elf) - Машинный код (алгоритм и логика программы)
- Адрес точки входа (например функции
main) - Данные (значения переменных, строки)
- Таблицы имен для однозначной идентификации принадлежности символов
- Информация о совместно используемых библиотеках и динамической компоновке, включая название компоновщика
С позиции ядра процесс является абстрактной сущностью, состоящей из памяти пользовательского пространства:
- код программы
- переменные
и ряда структур данных ядра:
- состояние процесса
- таблицы виртуальной памяти
- обработка сигналов
- ресурсы процессора
- текущий рабочий каталог
- …
Ядро изолирует процессы от взаимного влияния. Каждый процесс владеет изолированным адресным пространством. Процессы, нуждающиеся в обмене данными, должны явно организовать такой обмен посредством межпроцессного взаимодействия (IPC): каналов, файлов, базы данных и т.п.
Идентификация процессов
Каждый процесс имеет идентификатор (PID), за уникальностью которого следит операционная система. Кроме того, каждый процесс (за исключением init, PID которого равен 1) содержит идентификатор родительского процесса (PPID). Родительский процесс, в свою очередь содержит идентификатор своего родителя. Таким образом, ядро операционной системы обслуживает дерево процессов (см. команду pstree). Если процесс становится сиротой, ядро делает его родителем процесса init. В UNIX-подобных системах с интерфейсом коммуникации с ядром основанным на procfs (например BSD, Linux), родитель любого процесса может быть найден следующей командой:
# <PID> -- реальный идентификатор
grep PPid /proc/<PID>/status | awk '{print $2}'
Параллельное выполнение задач
Параллелизм (параллельное выполнение задач) заключается в выполнении нескольких операций одновременно. Реализация параллелизма может быть достигнута через порождение дополнительных процессов.
Порождение каждого нового процесса производится при помощи системного вызова fork(). Однако данная операция является дорогой с т.з. ресурсов и времени инициализации процесса. Для обеспечения более легковесной работы параллельных сопрограмм принято использовать потоки вместо процессов. Каждый процесс создается как минимум с одним потоком. Существует техническая возможность создавать дополнительные потоки внутри процесса.
Можно определить следующие ограничения создания дополнительных процессов:
- Каждый процесс выполняется в отдельном адресном пространстве. Это в свою очередь приводит к тому, что процессы не разделяют общую память
- Создание процесса с помощью
fork()занимает существенное время - Усложненный обмен данным между процессами (конвейеры, файлы, каналы и т.д.)
Модель конкурентного выполнения сопрограмм (concurrency) - это немного более широкий термин, чем параллелизм (parallelism). Данная модель предполагает, что несколько задач могут выполняться одновременно, но не говорит как это должно быть достигнуто. В англоязычном мире есть поговорка, “Concurrency does not imply parallelism”. Асинхронный ввод-вывод, не являющийся ни многопроцессным, ни многопоточным, тем не менее также подпадает под формулировку конкурентного выполнения кода. Резюмируя вышесказанное, многопроцессность это форма параллелизма (которого также можно добиться многопоточностью), а параллелизм в свою очередь, это подмножество конкурентного выполнения сопрограмм.
Схематично вышесказанное можно изобразить следующим образом:
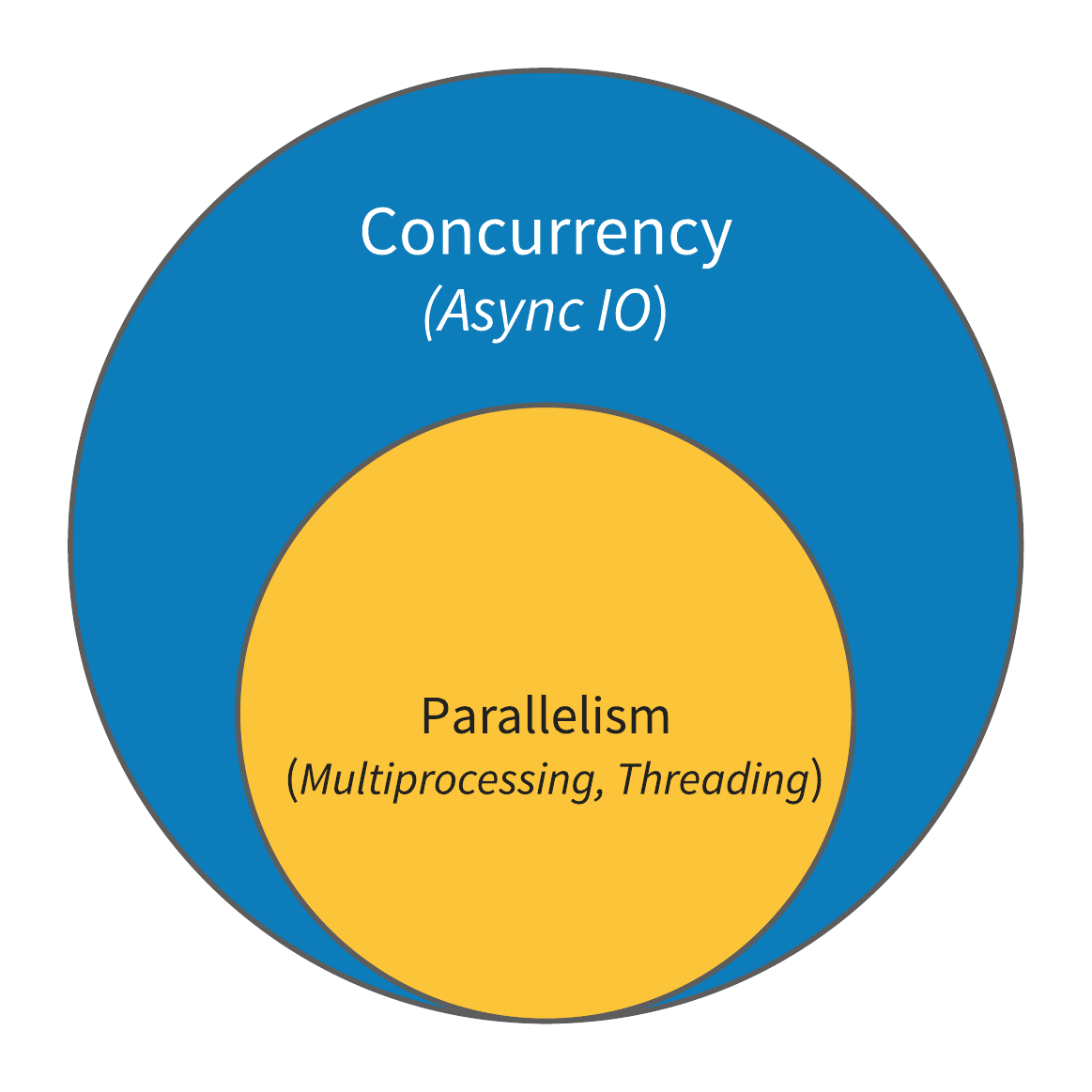
О потоках
По умолчанию процесс создается с одним потоком называемым главным или основным потоком. Потоки по существу являются дешевой копией процессов и по аналогии с процессами предоставляют механизм для одновременного выполнения нескольких параллельных задач в рамках одного приложения.
Техника программирования, позволяющая коду выполняться внутри единого процесса с помощью запуска нескольких потоков называется многопоточностью. Потоки могут выполняться как одновременно, так и нет. Одновременное выполнение потоков одного процесса называется параллелизмом (parallelism). Параллельное выполнение потоков в рамках одного процесса возможно только в многоядерных системах и не является обязательным поведением. В одноядерных системах многопоточность может быть только последовательной. Переводя на програмисткий язык: многопоточный код не обязан быть по определению быстрым или параллельным, но быть таковым он может.
Все потоки, выполняясь внутри своего процесса, разделяют общую глобальную память — данные и сегменты кучи. Это упрощает обмен данным между потоками процесса. Для этого всего лишь нужно скопировать данные в общие переменные (глобальные или в куче). Если поток изменяет ресурс процесса, это изменение сразу же становится видно другим потокам этого процесса. Тем не менее, каждый поток обладает локальным стеком для хранение локальных данных, которые доступны в рамках только текущего потока.
В Linux потоки реализованы с помощью системного вызова clone(), который как минимум в 10 раз меньше занимает времени для создания еще одного потока, чем создание еще одного процесса при помощи fork(). Такая скорость достигается за счет того, что многие атрибуты процесса разделяются между потоками.
Что важно знать о потоках, так это то, что они лучше подходят для задач, связанных с вводом-выводом. В то время как задачи ориентированные процессорные вычисления (CPU-bound), характеризуется постоянной интенсивной работой ядер компьютера от начала до конца, в задачах ориентированных на ввод-вывод (IO-bound) преобладает длительное ожидание завершения ввода-вывода.
Python
В Python существует модуль multiprocessing, позволяющий запускать дополнительные процессы и распределять вычислительную нагрузку между процессами параллельно, concurrent.futures предоставляющий высокоуровневый интерфейс к параллелизации сопрограмм, а также threading, предоставляющий высокоуровневый интерфейс к реализации параллельного выполнения кода с использованием многопоточности.
Литература
- Майкл Керриск. «Linux API. Исчерпывающее руководство». Питер, 2019.
- Роберт Лав. «Ядро Linux. Описание процесса разработки», 3-е издание. Вильямс, 2013.